Day 11 : 用於生產的機械學習 - Data Labeling 資料標註
tags: MLOps
 第 13 屆鐵人賽鍊成
第 13 屆鐵人賽鍊成標註資料與特徵工程是處理資料重要的步驟,目的都是為了讓模型效果最佳化,標註的一致性、特徵工程到位都對模型影響至關重要。現實生活情境的資料標註向來不是件容易的事情,但資料在變、世界在變,為了 ML 系統的健康,還是好好地面對 dirty work 吧。
標註資料
- 標註資料的方式可歸類為:
- 處理過程反饋 Process Feedback
- 人工標註 Human Labeling
- 半監督學習
- 主動學習
- 弱監督學習
處理過程反饋 Process Feedback
- 譬如網頁服務中,預測點擊與實際點擊的差異,這樣的差異可能紀錄在服務的 log 裡,重要的影響商業決策的可以捕捉特徵作為後續分析。
- Logstash
是免費且開源的數據處理管道,能從多個來源採集數據、轉換數據,然後發送至所需的儲存庫中。 - Fluentd 是一個開源的數據收集器,它可以讓您統一數據的收集和使用,以便更好地使用和理解數據。
- Google Cloud Logging、 AWS ElasticSearch、Azure Monitor 皆可完成相似任務。
人工標註 Human Labeling
-
相較自動標註,較耗時、成本較高,而且有些資料人看不懂很難標註(像是 CT、MRI 需要專業判斷)。好處是比較能掌控。
-
人工標註通常不是一個人的事情,不是找個研究生/工讀生就可以搞定,在不同人、不同時空進行標註,需要有「標註指引」來協助標註一致。
-
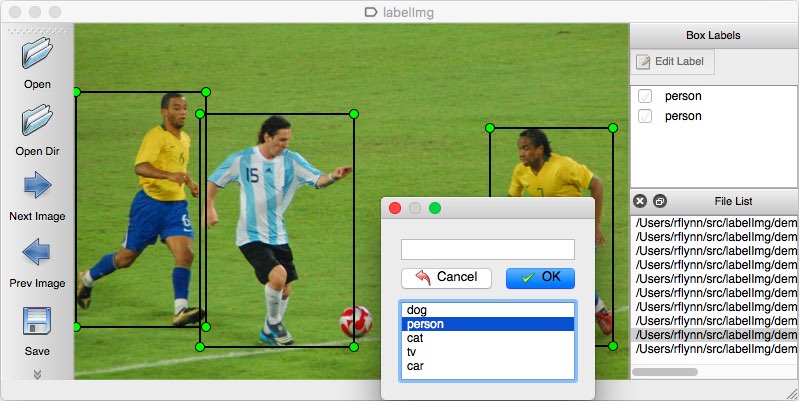
圖像的標註:

- 特徵邊界不一致、標籤也不一致。
- 有了「標註指引」方便團隊溝通或喚醒回憶,指引包含建議標註方式、正確/錯誤樣態範例。
-
語音的標註:
#如果是您要如何讓以下記錄方式一致?
A: 嗯...下次會議在11/01舉行。
B: 嗯,下次會議再11/1舉行。
C: 下次會議在11月1日舉行。
D: [語助詞]下次會議在11月1日舉行。- 例如會議紀錄逐字稿,常見的是語助詞認知不同,採取統一的文字標註方式(譬如採取 B 方案)整理後較為理想。
-
雜訊的處理:
- 文字、語音、影像等資料集,如果遇到雜訊影響模型判斷之處,可以再增加欄位描述。
- 譬如語音判斷弱點在室內吵雜處、室外車流處,增加欄位以標示是否在前述情境。
- 影像在昏暗處、模糊處也可以增加欄位標示情境。
- 如果是連專業人士都無法準確判斷的雜訊,不建議讓電腦學習,訓練結果較不可控。
-
標註工具:
半監督學習 Semi-supervised Labeling
- 指由人工標註一部份資料(監督式學習),其餘資料集透過非監督式學習完成。
- 應用最好的監督、非監督方法,使用少量的標註提升模型準確性。
- 李弘毅老師 2016 年 ML Lecture 12: Semi-supervised
有推導過程可參考。
主動學習 Active learning
- 選擇最重要的樣本去標註。
- 提升預測準確性。
弱監督 Weak supervision
- Snorkel 是弱監督的方便模組。 Snorkel 為史丹福於2016年發起的專案,讓使用者能夠以程式方式標記、構建和管理訓練數據。
系統化標記作法
- 舉例 Azure 在建立資料標記專案和匯出標籤說明,影像與文字標註皆可在 Azure 完成,當初使化 ML 專案後,「儀表板」索引標籤會顯示標籤工作的進度。
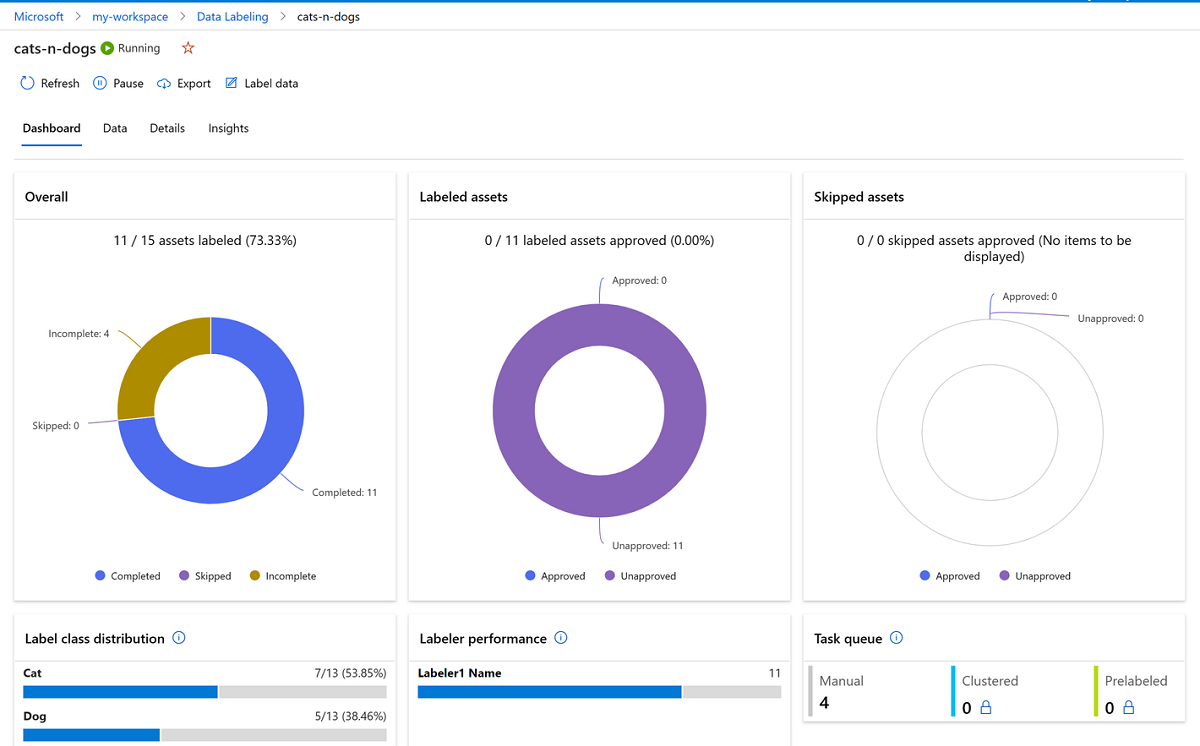
- 圖片來源: Azure 建立資料標記專案和匯出標籤。
小結
- 人工標註是較可控,但耗時費力又花錢的做法,大量未標註的資料可以透過半監督式學習、主動學習、弱監督等方式取得協助批次標註的效果。
- 如果可以採取雲端平台商的一系列解決方案,會減省資料整合的時間,相對會比開源解決方案較經濟,就看評估取捨。